The need for a logical and systematic way to organize and control revisions (versions) has existed for almost as long as writing has existed.
Its practices can be found in different domains and in almost anything that we use in our daily lives – books, mobile phones, laptops, home appliances, vehicles and most importantly in our tech world – software.
Why is it so important ? Why should we care ? What are …, Where can I ….When to ….
Lets fill in these blanks as we explore the chapter of Version Control.
Background
Have you ever spent time copying your work files into a certain directory (sometimes, maybe with a time-stamp and a short name) just with a thought of keeping a backup or to mark a point in history in order to track down your changes over time and then moving on to complete the next phase of your work ?
– If your answer is YES !! or somewhere near it, then you are already practicing versioning a little.
This approach of versioning is often referred to as traditional version control. And note my advise, you are not the only one practicing this approach. Developers and IT guys had been using this technique since early days of computing.
It is a very wise thing to do, but sometimes things can go south without realizing. Lets know why –
- copied the wrong file
- accidentally wrote to a wrong file
- forgot which was the last edit
- cant locate a certain file at a certain point in time – too many directories
- when did things start to spoil – error prone files
Definition
A simple definition of a Version Control System in the software world would be :
A system that records changes to a file or a set of files over time so that you can recall a specific version later.
- revert selected files back to a previous state,
- revert the entire project back to a previous state,
- compare changes over time
- see who last modified something
- easy recovery from lost files or screwed up things
1st Generation VCS - Local Version Control

The first generation of version control systems dates back to the 70`s.
Developed by the early Unix developers in 1972 at Bell Labs (by Marc Rochkind for an IBM System/370 computer) called Source Code Control System (SCCS).
The other popular one was Revision Control System (RCS) developed as a successor and an alternative tool to SCCS in 1982 by Walter F. Tichy at Purdue University. It works by keeping patch sets(i.e different between each files) in a special format on disk; later on we can re-create what any file looked like at any point in time by adding up all those patches.
The idea behind local version control systems of that era was that, they followed the local data model i.e. they had a simple database that kept all the changes to files under version control. All developers had to us the same file system.
2nd Generation VCS - Centralized Version Control
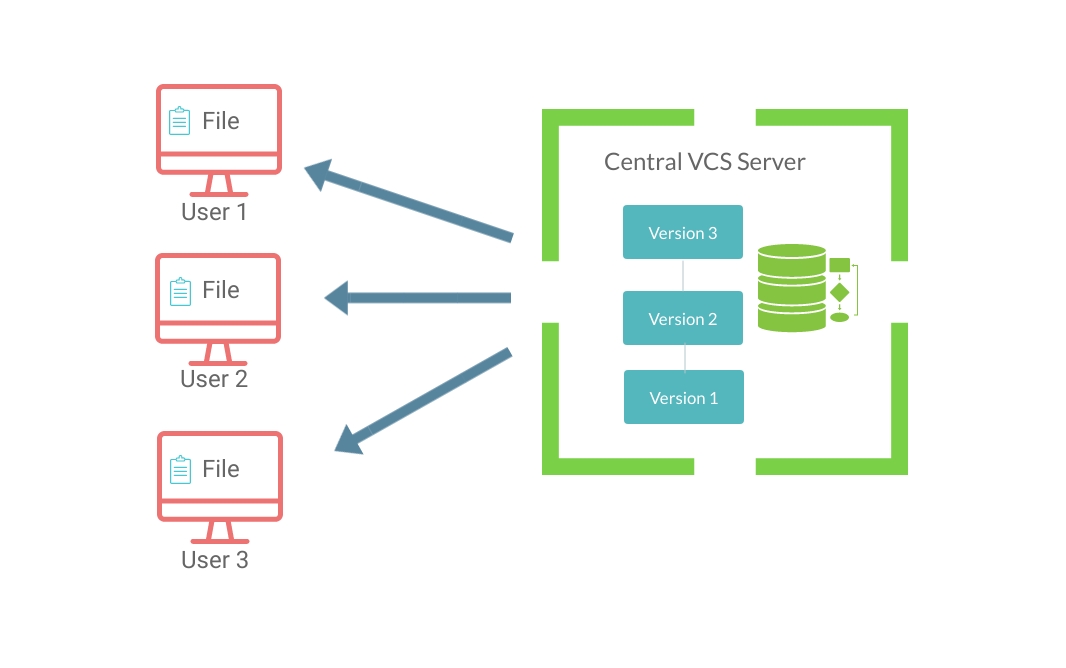
Second generation VCS followed the client-server model.
They were developed primarily to tackle a particular problem in software development – i.e. to collaborate with developers on multiple systems.
These systems have a single server that contains all the versioned files. Each developer then on their local system, check out files from this central server.
Advantages :
- Everyone can be on sync with everyone else regarding what they are all doing
- Easy administration and better control over role assignments
- Locking mechanisms for non-mergeable binary files
Disadvantages :
- Single point of failure (If the central server is damaged somehow, everything, the entire history is gone)- any centralized server will have this downside
- The server had to be up and running all the time for the team to collaborate
3rd Generation VCS - Distributed Version Control
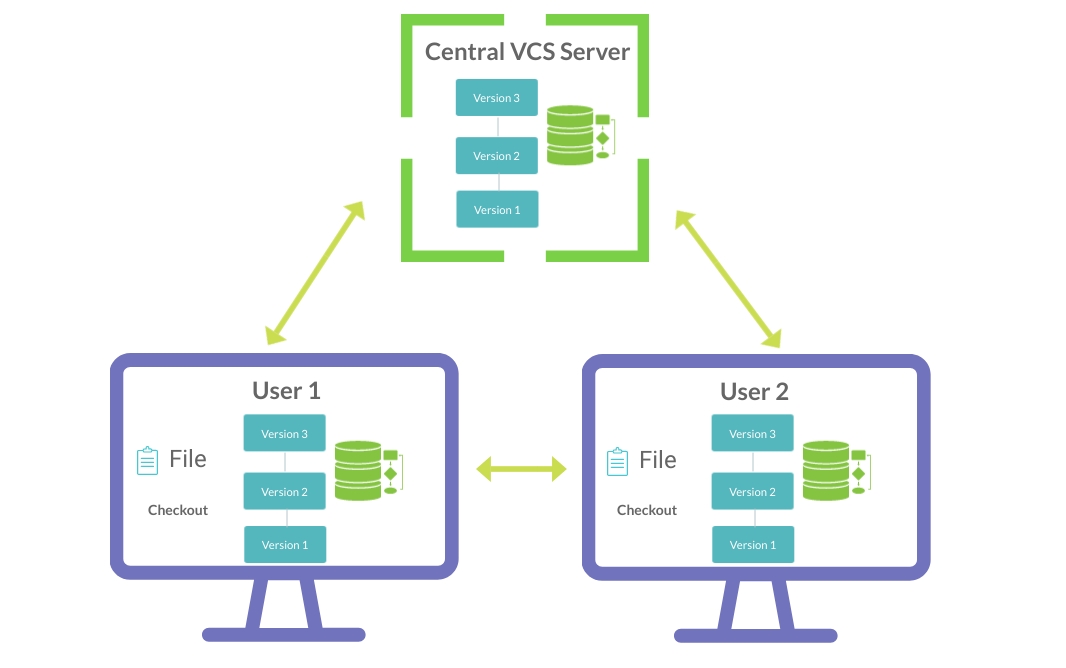
These are the modern version control systems that are widely used today and they follow the distributed model (peer-to-peer).
Instead of just checking out the latest snapshot of the files; you will be fully mirroring the repository including its full history. Its like having you own server locally, working in collaboration and in sync with other servers including the master server.
This way, even if one server dies, any other clients repository can be copied back up to the server to restore it.
Advantages :
- No need of active dependency with the central server
- Easy backup
- Faster operations (commit, view history, revert)
- Private versioning
- Feature Branching and merging
- Ability to setup multiple types of workflows – (collaborate with multiple remote repositories in multiple ways simultaneously)
- Allows various development models to be used, eg: development branches or commander/lieutenant mode
- Additional storage required (for complete codebase and history)
- Lack of locking mechanisms – for non-mergeable binary files such as graphic assets or too complex single file binary or XML packages (eg: office documents, PowerBI files, SQL Server Dta Tools BI packages etc)
- Initial checkout of a repository is slower as compared to checkout in a centralized VCS.

